一、分布式场景下数据库架构方式
1. Share nothing
顾名思义,就是什么都不共享。
Mysql 的分库分表和大部分的Nosql都是这样的方案,底层实际上完全分离,节点之间单独计算,不共享数据。
好处很明显,设计简单,扩展灵活,并行度较高。
缺点也很明显,跨分片查询困难,数据一致性难以保证。
能够实现强一致的只有zookeeper这种轻量级的分布式存储框架,但是它是牺牲了可用性的前提来保证的一致性,这也是Kafka和Dubbo这种主流中间件在逐渐抛弃zookeeper的原因,详见Zab1.0。
2. Share disk(或者Share storage)
这其实是计算、存储分离的架构,上层由多个无状态的计算节点组成,他们共享统一管理的数据存储集群。
比如亚马逊的Aurora和阿里的PolarDB,都是采用这种架构方式。
下图为PolarDB的架构:
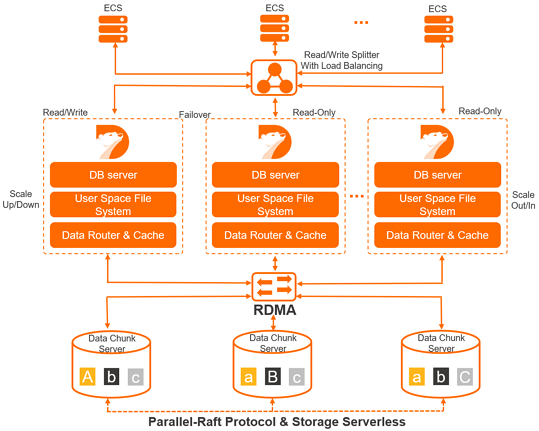
可以看到,上层计算节点完全分片,通过RDMA(远程直接数据存取)进行数据传输。下层由多个数据服务组成,并通过Parallel-Raft协议保证一致性。
这其实也是硬件发展过程中,网络I/O速度不断追上磁盘I/O速度的体现。
二、主流方案介绍
1. Mysql分库分表
Mysql通过mycat、sharding-jdbc等进行分库分表方案,从源头上说,这并非一种产品而是架构方案。
分库分表后主要问题有如下几方面:
首先是数据不在一起,所以无二级索引。
强需求二级索引场景下,可能需要自建二级索引。由此又带来一致性问题,因为索引和数据不在同一个节点上。那么不同节点间调用,至少发生一次网络IO,这就增加了可用性问题。
但是,好处是显而易见的。
方案成熟,知识获取、人才储备都非常容易,Mysql又极其稳定,相关方案可信度较高。
2. TiDB
国产开源数据库,属于Share nothing架构,高度兼容Mysql,水平弹性扩容,支持标准的ACID事务。
基于Raft协议,提供金融机构的100%数据强一致性保证,且提供auto-failover方案。
且内部提供Spark能力,所以同时包含了OLTP和OLAP特性。
相比较Mysql来说,硬件成本高,依赖SSD,部署组件多,运维难度高。但是国内很多大型项目采用了,并且提供了很多的踩坑经验。
对于数据库来说,索引、唯一约束、主键约束、外键约束、DDL等都依赖事务,在分布式数据库领域下,事务的核心在于可见性。
一致性和原子性有各种log、MVCC的方案来保证。但是可见性只能依赖于分布式锁或者分布式MVCC。
-
分布式锁实现上,如何解决分布式死锁是困难所在。
-
分布式MVCC方案,Mysql并没有暴露数据版本,所以想做MVCC,数据的实时合并非常困难。
针对这个问题,TiDB数据版本控制使用的是事务启动时获取的全局读时间戳。
下图是TiDB的架构:
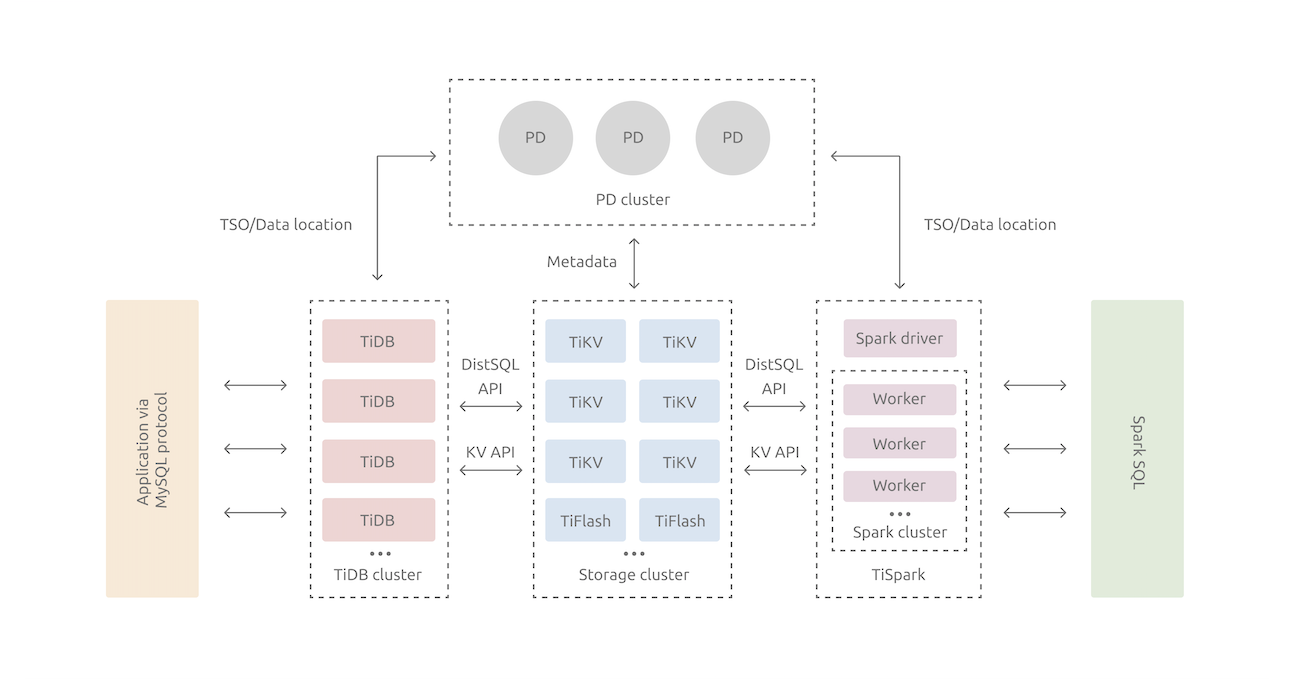
可以看到,整个服务由TiDB集群统一通过Mysql协议对外提供服务,存储集群由多个TiKV和TiFlash节点组成,而TiKV自身存在独立计算能力,且各个TiKV之间并不共享数据,所以属于为Share nothing架构。
3. PolarDB
云原生数据库,实现了计算节点(主要做 SQL 解析以及存储引擎计算的服务器)与存储节点(主要做数据块存储,数据库快照的服务器)的分离,提供了即时生效的可扩展能力和运维能力。
闭源产品,原理理解全靠官网介绍,介绍文档表示,各种对比领先TiDB、OceanDB等。
共享存储型数据库的特点,写节点只有一个,所以较好的保证事务特性,性能问题依靠SSD和高带宽网络这种高硬件标准来保证。