Dubbo架构
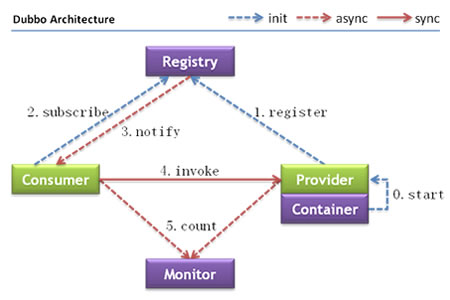
| 节点 | 角色说明 |
|---|---|
Provider |
暴露服务的服务提供方 |
Consumer |
调用远程服务的服务消费方 |
Registry |
服务注册与发现的注册中心 |
Monitor |
统计服务的调用次数和调用时间的监控中心 |
Container |
服务运行容器 |
支持注册中心
-
nacos
-
zookeeper
-
redis
-
multicast
-
simple
常用协议
-
dubbo(默认)
采用NIO单一长连接
-
rmi
基于tcp协议
-
hession
基于http协议
远程通讯组件
-
netty
-
mina
-
grizzly
支持序列化方式
- hession
- dubbo serialization
- json
- java serialization
Stub的生成方式
-
Javassist ProxyFactory
通过字节码生成代替反射,性能比较好
-
Jdk ProxyFactory
JDK原生支持,性能较差
容错策略
| Feature | Strength | Problem |
|---|---|---|
| Failover Cluster | 失败自动切换,当出现失败,重试其它服务器,通常用于读操作(推荐使用) | 重试会带来更长延迟 |
| Failfast Cluster | 快速失败,只发起一次调用,失败立即报错,通常用于非幂等性的写操作 | 如果有机器正在重启,可能会出现调用失败 |
| Failsafe Cluster | 失败安全,出现异常时,直接忽略,通常用于写入审计日志等操作 | 调用信息丢失 |
| Failback Cluster | 失败自动恢复,后台记录失败请求,定时重发,通常用于消息通知操作 | 不可靠,重启丢失 |
| Forking Cluster | 并行调用多个服务器,只要一个成功即返回,通常用于实时性要求较高的读操作 | 需要浪费更多服务资源 |
| Broadcast Cluster | 广播调用所有提供者,逐个调用,任意一台报错则报错,通常用于更新提供方本地状态 | 速度慢,任意一台报错则报错 |
负载均衡策略
| Feature | Strength | Problem |
|---|---|---|
| Random LoadBalance | 随机,按权重设置随机概率(推荐使用) | 在一个截面上碰撞的概率高,重试时,可能出现瞬间压力不均 |
| RoundRobin LoadBalance | 轮询,按公约后的权重设置轮询比率 | 存在慢的机器累积请求问题,极端情况可能产生雪崩 |
| LeastActive LoadBalance | 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差,使慢的机器收到更少请求 | 不支持权重,在容量规划时,不能通过权重把压力导向一台机器压测容量 |
| ConsistentHash LoadBalance | 一致性Hash,相同参数的请求总是发到同一提供者,当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动 | 压力分摊不均 |
注册中心的选择
由于zookeeper的多功能特点,很多分布式系统在初期搭建时都选择使用zookeeper来实现其中某项功能如服务治理、数据存储、分布式锁等。
zookeeper天生遵守CP原则,即保证一致性和分区容错性,但无法保证可用性。
对于RPC服务的服务发现来说,并不需要强一致性,而是需要高可用。某个节点信息不一致并不会造成严重后果,但选举的过程中整个zk集群不可用是不能接受的。
所以无论是RPC服务还是消息队列,都在逐渐抛弃使用zookeeper,比如dubbo开始推荐使用nacos,Kafka则在2.8版本中正式废弃了Zookeeper,拥抱Raft协议
线程模型
<dubbo:protocol name="dubbo" dispatcher="all" threadpool="fixed" threads="100" />
Dispatcher
all所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。direct所有消息都不派发到线程池,全部在 IO 线程上直接执行。message只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 IO 线程上执行。execution只有请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 IO 线程上执行。connection在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
ThreadPool
fixed固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省)cached缓存线程池,空闲一分钟自动删除,需要时重建。limited可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。eager优先创建Worker线程池。在任务数量大于corePoolSize但是小于maximumPoolSize时,优先创建Worker来处理任务。当任务数量大于maximumPoolSize时,将任务放入阻塞队列中。阻塞队列充满时抛出RejectedExecutionException。(相比于cached:cached在任务数量超过maximumPoolSize时直接抛出异常而不是将任务放入阻塞队列)
工作流程
假设A服务调用B服务的场景:
-
A与B通过远程通讯工具(比如socket)建立通讯
-
由于底层通讯使用二进制,所以要将参数放入Request对象中序列化成二进制
-
B服务通过自己的通讯工具接收请求,并将其反序列化成请求对象,然后调用对应方法(java中使用反射)
-
执行完毕,B服务按照原来的流程,将结果发送给A服务