前言
互联网时代的用户爆发式增长,为了提供系统的可靠性、可扩展性、高性能等特点,分布式的架构方式应运而生。
想提供7x24的业务可用性,就必须让同一份数据存储在不同机器上用作备份。
为了解决并发高的问题,单一机器无法满足要求,就需要水平增加更多的机器来提升性能。
这就是分布式下的两个核心问题:复制和分区。
复制
1 为什么要复制
高可用性
当一个数据节点出现问题不能响应请求时,系统仍可以通过将请求打到其他数据节点上来保证系统的整体可用性。
低延迟
当系统为广泛地域提供服务时,可以将用户的请求分发到空间距离较近的数据中心以提供较低延迟的服务。
可扩展性
当请求并发量增长到单机无法承受时,多节点分摊读写压力成为必然的选择。
2 复制的方式
2.1 预写日志复制
通过传输WAL预写日志来同步数据,缺点是预写日志包含数据的物理信息,数据结构非常低层,这就意味着传输的数据和存储引擎紧密耦合,数据库升级版本时向下兼容变得非常困难。
2.2 逻辑日志复制
逻辑日志中通常记录的是数据变更的逻辑,典型使用就是Mysql的Binlog(它也是Mysql同步和崩溃恢复的主要方式)。
逻辑日志不仅有良好的兼容性,也有更好的可读性,通常可以由外部系统解析后进行其他行为。
抛开这些优点,逻辑日志和预写日志相比,主要问题是数据复制时,前者写入需要解析、编译、优化等等步骤,后者则可以直接写入。
2.3 触发器复制
很多数据库支持配置触发器,当发生数据变更时,由触发器去调用应用层的用户自定义逻辑,比如将数据复制到另一个系统。
触发器复制机制开销更高,也更容易出错,但具备了更高的灵活性。
3 同步复制 or 异步复制
采取同步的方式来复制数据通常是为了保证可靠性,但同步等待全部从机完成写入时,从机数量越多显然整体性能越差。
所以对于写入性能要求较高的场景一般采取“一同多异”的方式:有一台从库写入完成(至少成功返回日志写入成功的标识,如mysql的relay log),就提交事务,其他从库采取异步复制的方式。
4 复制方案
主从复制
通常主节点用来承担写入场景,数据同步到从机后,由从机承担数据读取任务。
主从复制场景下,数据流向单一,不存在多节点写入冲突的问题,但最直接的问题就是如果主节点出现问题,所有写入操作都将会收到影响。
多主节点复制
为了解决主从复制下单一主节点可用性较低的问题,最直接的解决方式当然是使用多个主节点。
多主节点复制相比主从复制的优势:
-
性能
单一主节点处理所有的写请求,必然对单节点性能有更多的考验,相比之下,多个主节点能够分摊写请求,再通过异步的方式将数据同步到其他主节点。
-
分区容忍
一主多从下,主节点宕机需要将其某一个从节点升级为主节点,在此期间,集群丧失写入能力。但多主的方案,则没有这个问题,某一个主节点宕机后,等待其恢复即可。
多主节点复制的主要问题是难以处理并发写入造成的数据冲突。
无主节点复制
核心思路是将写入请求发送给多个副本,读取时从多个节点并行读取,根据Quorum公式来确认写入成功和读取成功的最小副本数。
这个方案的复杂点是:
-
该方案需有集群有协调能力,可以设定独立的协调节点,也可以由收到请求的节点作为协调者,并将请求分发到其他节点。
-
更好的容错性,是通过至少3倍以上的硬件成本做支撑达到的。
-
与多主复制的方案具有相同的写入冲突问题
5 Quorum
Quorum [ˈkwɔːrəm]
n.(会议的)法定人数
[牛津词典] the smallest number of people who must be at a meeting before it can begin or decisions can be made
假设有N个副本,我们设定其成功写入W个服务即判定为写入成功(其他副本可能在异步写入过程中),那么读取数据时,至少要读取R个副本。R是多少呢?
如果要保证R中副本包含最新写入的数据,那么就需要W和R之间一定有重叠,即:W + R > N
通常N为奇数,且至少为3,W = R = (N + 1) / 2
6 一致性模型
写后读(read after write)
保证同一个用户更新数据后,再次读取数据应该是自己更新过的最新版本。
为保证写后读一致性,可以采用如下方式:在用户写入成功后的一分钟内,该用户的读取行为被指向跟写入相同的节点。
单调读
用户每次读取的数据版本不会比上一次读取的版本更早。
前缀一致读
当一组串行事件保存在不同节点中后,再将其从各个节点汇总起来,应当保持相同的串行顺序。
可以将同一组事件发送到相同节点,比如对事件关键字使用Hash来匹配节点。
7 并发场景下如何解决冲突
由于分布式系统中复杂的时钟同步问题,现实当中,我们很难严格确定它们是否同时发生。
为更好地定义并发性,我们并不依赖确切的发生时间,即不管物理的时机如何, 如果两个操作并不需要意识到对方,我们即可声称它们是并发操作 。
– 《DDIA》第五章:数据复制 Page.178
避免冲突
处理冲突最简单的方式就是避免冲突,一般做法是把相同用户的请求永远路由到相同的节点进行处理,比如在代理层做Hash类型的负载。
解决冲突
解决冲突可能有以下方案:
-
最后写入者获胜(Last Writer Win)
为每个请求增加序列号,可以是有序的序列号,如时间戳,或者无序的序列号如UUID。时间戳包含时间概念,更容易确定是谁“后写入者”,但由于有“时钟问题”,所以也不能完全信任。
-
为节点分配唯一值
合并冲突时,保留序列号较大的副本的请求。
-
连接冲突
将冲突通过连接的方式保存在一起,但这种方式使字段缺少逻辑性。
-
保留冲突
将冲突保留在一起,并最终反馈给用户,由用户人为决定如何解决该冲突。
-
自定义冲突解决逻辑
某些系统提供钩子函数,可以由用户自定义该钩子函数的实现来提供解决冲突的判定逻辑。通常可以在写入时执行或者读取时执行。
分区
一、数据分区的方式
1. 根据关键字范围分区
优点
- 分区逻辑带有业务属性或者数据特征,所以便于范围查询。
- 一般场景下,比如根据时间分区,可以根据数据量级自动增加分片以扩容,且不涉及扩容后的数据迁移
缺点
- 更容易造成数据热点问题(同一时间请求相邻数据会造成所在分区热度过高)
2. 根据关键字哈希值分区
哈希方式可以使用MD5,或者一些加密性相对较差但性能较好的哈希算法,如Fowler-Noll-Vo函数。
而哈希值对于分区的映射,可以由所有分区均匀分摊,或者使用一致性哈希算法。二者区别在于一致性哈希的动态平衡特性会使分区再平衡变得不可控:新增一个分区会导致所有旧分区都需要进行数据迁移来保证数据平衡。
优点
- 最大优点在于分区均匀
缺点
-
范围查询困难,通常需要查询所有分片。
比如mongo和es范围查询时需要将请求发送到所有分片后对结果进行汇总,而某些数据库干脆不支持范围查询。
-
扩容往往伴随数据迁移
热点问题
基于hash分区只能让数据分布更均匀,但仍旧避免不了热点key所在分区会承受更多的请求流量的问题。
那么通常解决办法是在热点key的后缀增加随机数,使数据分摊到更多的分区上,这样所有的分区分摊了写请求的压力。缺点是读取该key时需要查询所有随机数组合的key,然后将结果进行合并。
所以对热点key增加多级缓存在很多场景下更为合适。
二、分区数据如何索引
基于文档分区的二级索引(本地索引)
每个分区完全独立,维护自己的二级索引,因此也被称为本地索引。
优点是索引容易维护,但查找某项数据时,不能保证数据全保存在同一个分区内,所以需要访问所有分区的二级索引,并将结果进行汇总。
基于词条的二级索引分区(全局索引)
所有数据统一进行索引,然后将索引分片存储到不同的节点上。
所以查询某一项数据的执行顺序是:先定位到该查询项所对应的索引所在位置,然后通过索引找到数据所在节点。
优点是读取方便,但是写入复杂性大大提高,尤其当一条数据对应多个二级索引时,且这些二级索引并没有存在一起,那么可能需要对多个节点进行更新而造成写放大。而且还需要分布式事务来对多个节点内索引进行更新,这又降低了写入速度。
三、分区数量变化
当集群内分区数量变化时,需要进行分区再平衡来让数据在集群内分步均匀,再平衡的方式通常分为自动和手动:
-
自动
可以通过取模确定节点和分区的匹配关系,但扩缩容时频繁的数据迁移,导致该方案几乎不被使用。
-
手动
手动指定节点和分区的匹配关系,该方案更可控,比如Redis的哈希槽的映射关系初始化时可以根据分区数量均匀划分,但变更时需要手动维护。
四、请求的分区路由策略
数据落到不同分区后,需要路由策略来使请求被正确分发到对应的分区所在的节点,而这个路由策略可以维护在客户端、节点,或者在二者之间增加路由层。
1. 路由策略存储在节点
每个节点都保存节点和分区的映射关系,请求随机打到某个节点下,然后通过该映射关系找到真正需要访问的分区所在的节点。这种方案提高了复杂性,映射关系需要在各个节点保证低延迟的一致性,但这个节点数量成反比。好处是减少了对ZK的依赖,众所周知ZK是AP应用,强一致性的缺点就是选举时不能对外提供服务。

2. 路由策略存储在客户端
将分区和节点的映射关系下发到客户端上,让客户端能够定向找到对应节点。
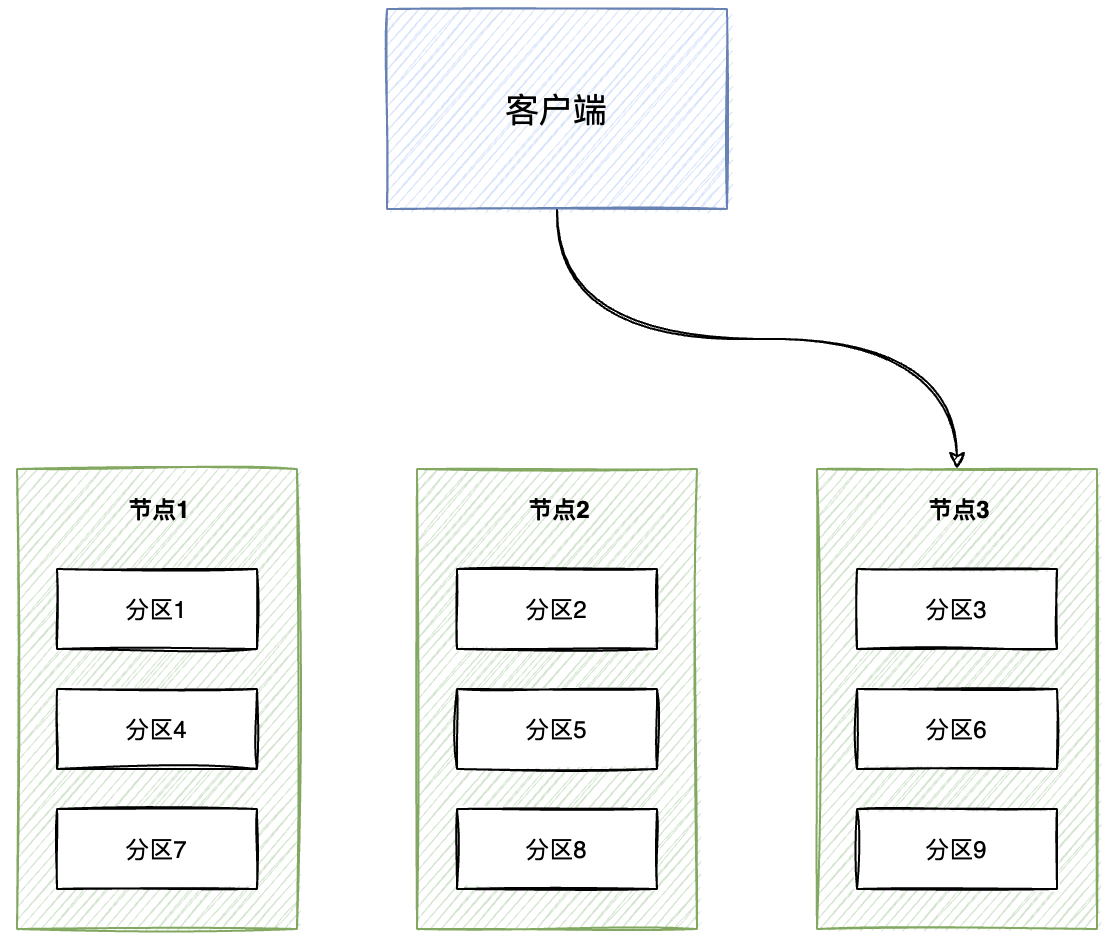
3. 路由策略存储在路由层
路由层承接所有的请求,并将请求分发到对应分区节点上。比如通过ZK来维护节点到分区的映射关系。
